
BEA : Kesaco ?
BEA est l’acronyme de Bots Events Analysis. Je réutilise le terme proposé par @VincentTerrasi.
L’objectif est d’analyser les requêtes des robots de moteurs de recherche pour améliorer son site, son SEO.
Ici, je vais surtout vous montrer un aperçu de ce qu’on a dans le « lab Cocon », en mettant l’accent sur l’aspect visualisations.
Il s’agit pour le moment d’expériences, sur des jeux de données limités.
L’analyse de logs pour le tracking des bots
Je ne vais pas revenir sur les bases, je suppose que vous savez que chaque serveur web (que ce soit apache ou nginx) génère des logs pour chaque requête reçue.
Ces logs bruts (pas besoin de marqueur javascript, ni de solution tierce) contiennent tout ce dont on a besoin pour suivre, notamment, le parcours et le comportement des robots d’exploration sur son site.

En pratique, on va filtrer les lignes en fonction du User Agent de chaque demande, pour ne conserver que les lignes qui nous intéressent.
Dans la suite par exemple, on sélectionne les user agent correspondant soit à GoogleBot soit à BingBot.
Après tout, ce n’est que logique : les moteurs ne se gênent pas pour nous traquer et en exploiter les données, pourquoi ne leur rendrions nous pas la pareille ?
L’approche du cocon :
Chez cocon, on n’est pas fan de débauche de moyens et de cpu. Dans nos expériences, on a fait simple et efficace.
On prend les fichiers de logs bruts, en regroupant par semaine ou par mois selon ce qu’on veut.
Une petite moulinette permet de filtrer (très rapidement) ce fichier texte, et donne en sortie un joli fichier Json qui contient tout ce qu’on veut, pour chaque bot :
– le nombre de « hits » sur chaque page
– les sessions de chaque bot avec le parcours de chaque bot
On a ainsi un fichier de taille raisonnable, qu’un navigateur peut gérer en RAM sans souci.
Ce script « moulinette » finira peut être un jour en open source.
En prévision : on peut également se brancher sur une base ElasticSearch si vous avez déjà une stack ELK ou ELG
(Ce qui est le cas de l’offre OVH PaaS Logs)
Les visualisations du labo
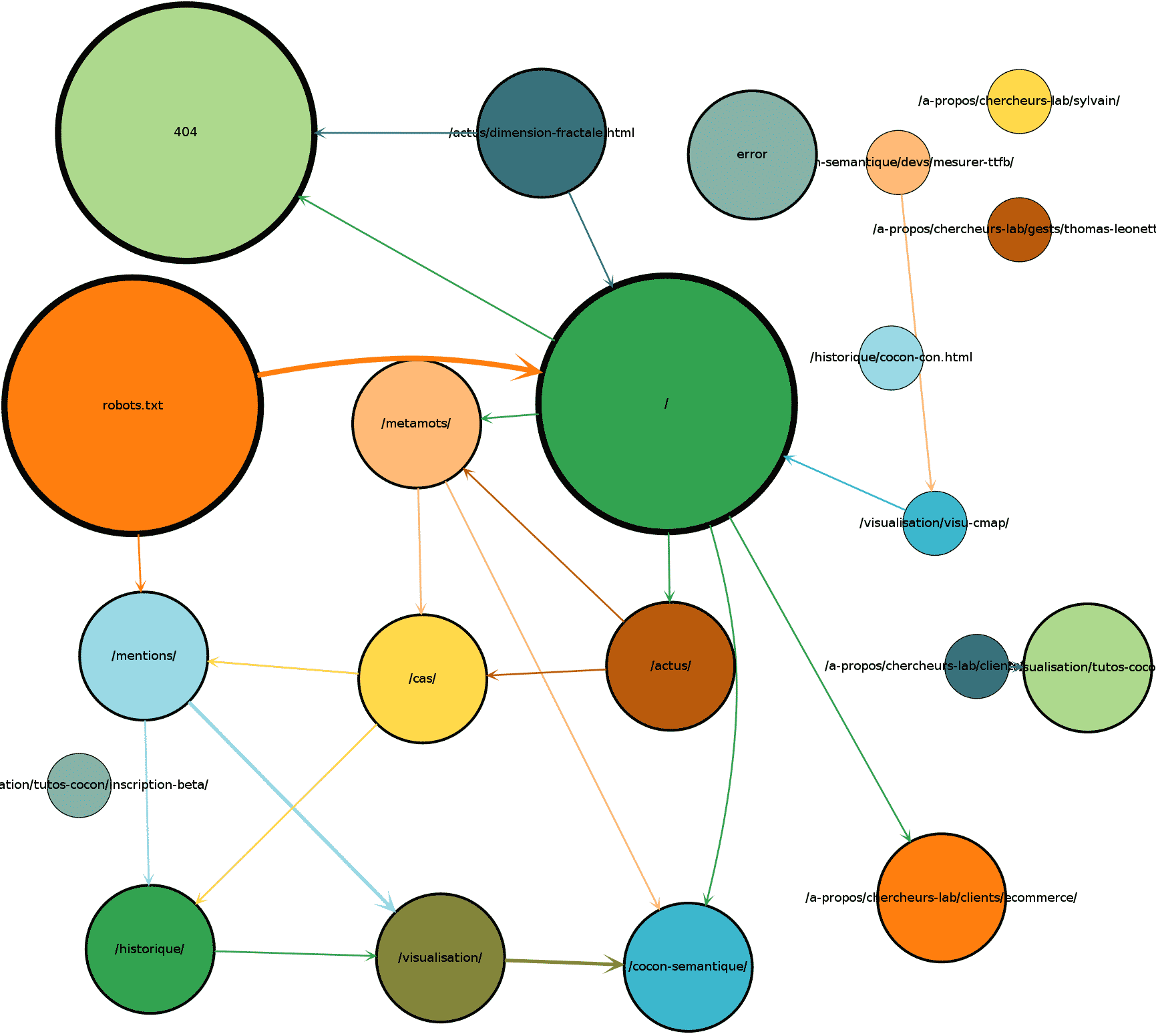 Pour les premières expériences, pas besoin de faire compliqué.
Pour les premières expériences, pas besoin de faire compliqué.
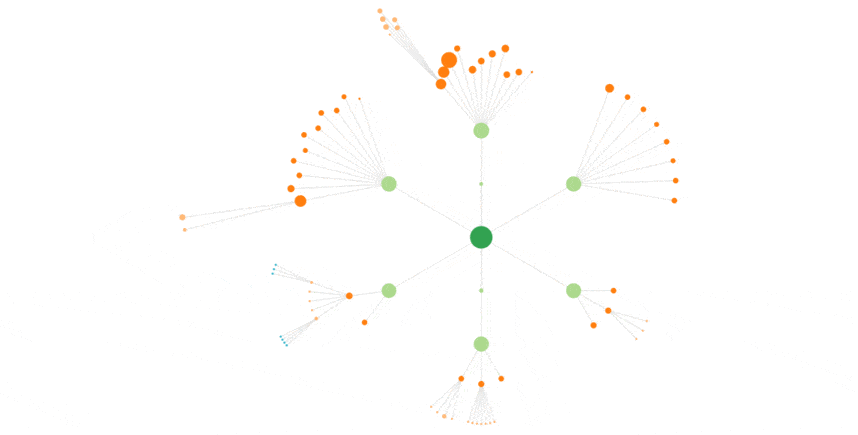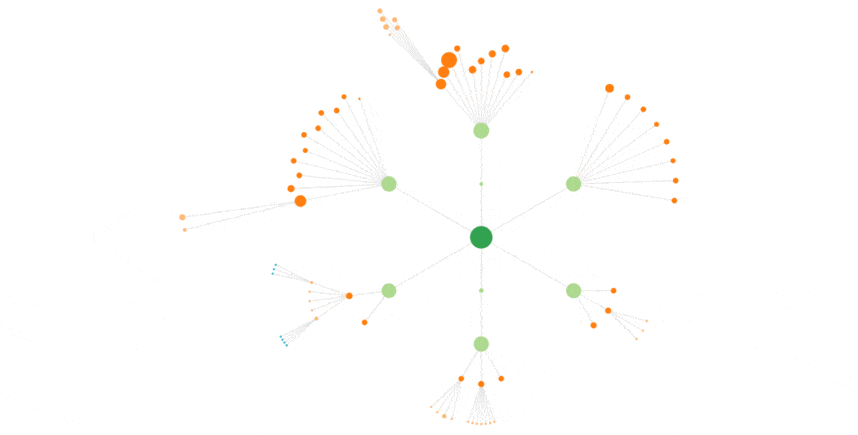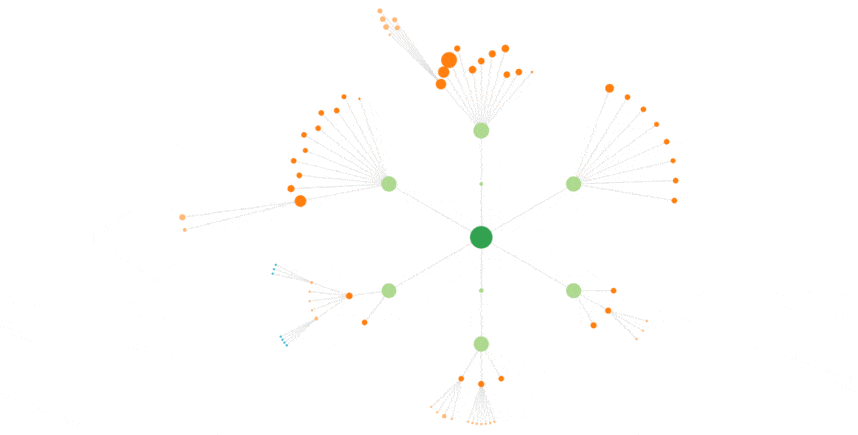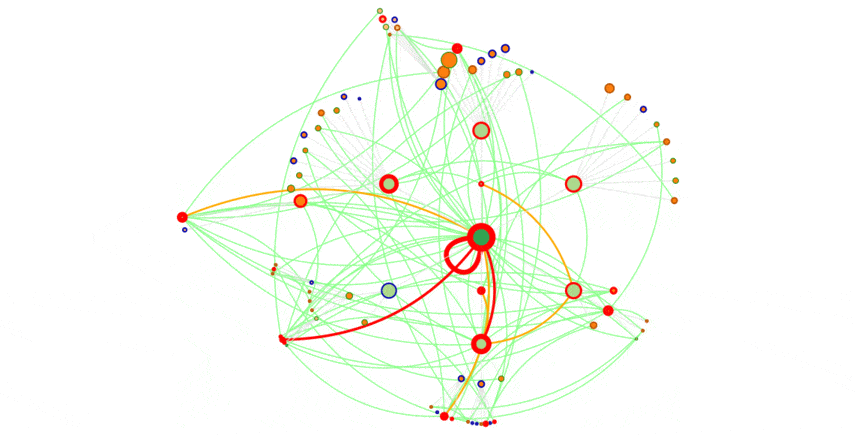
Je représente chaque page par un disque de couleur.
Le rayon du disque est proportionnel au nombre de hits reçu.
(j’évite de faire des bulles qui contiennent l’url, ça cela donne plus d’importance perçue aux urls longues)
Ensuite, je représente les « chemins » qu’ont suivis les bots au cours d’une session.
Ici aussi, plus le chemin est emprunté, plus le lien est épais.
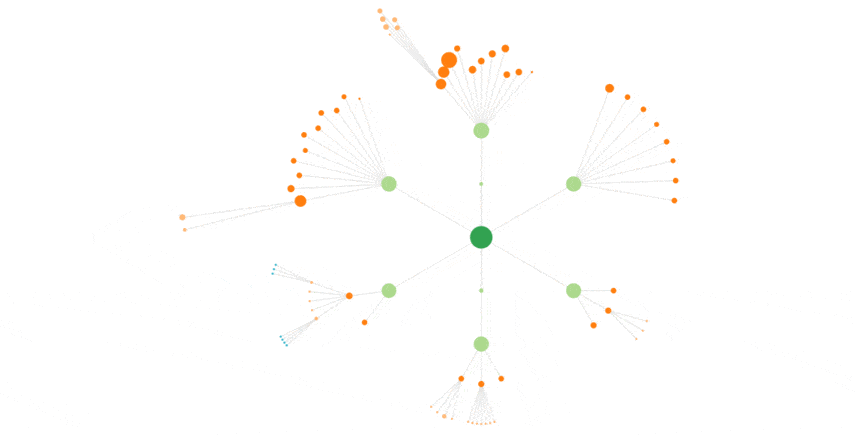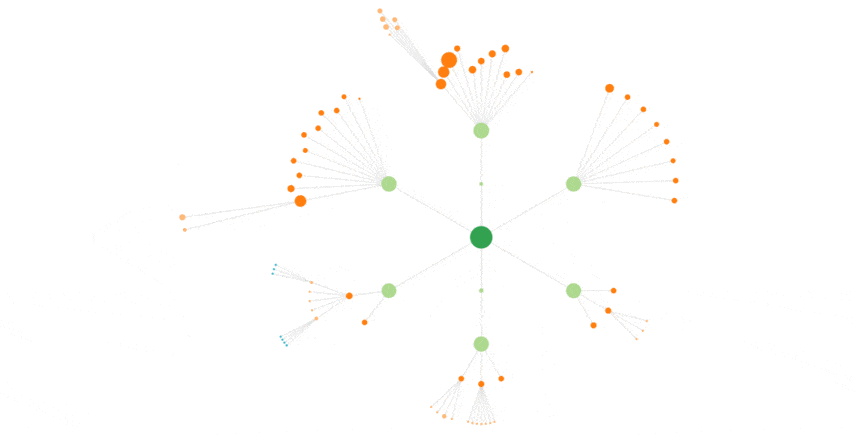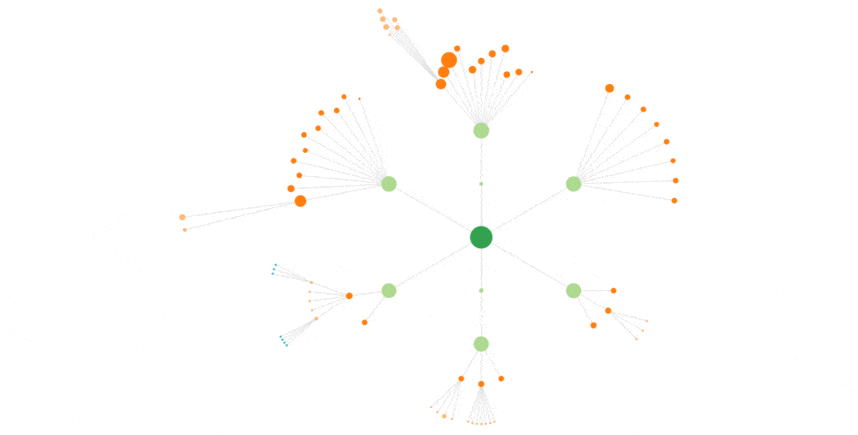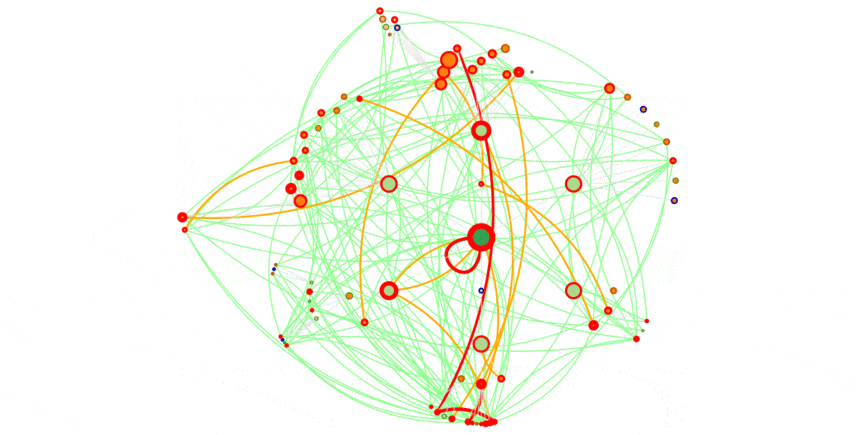
à droite, vous voyez ce que ça donne pour Googlebot sur Cocon.Se, pour une petite semaine.
Ci-dessous, toujours GoogleBot sur un mois complet :
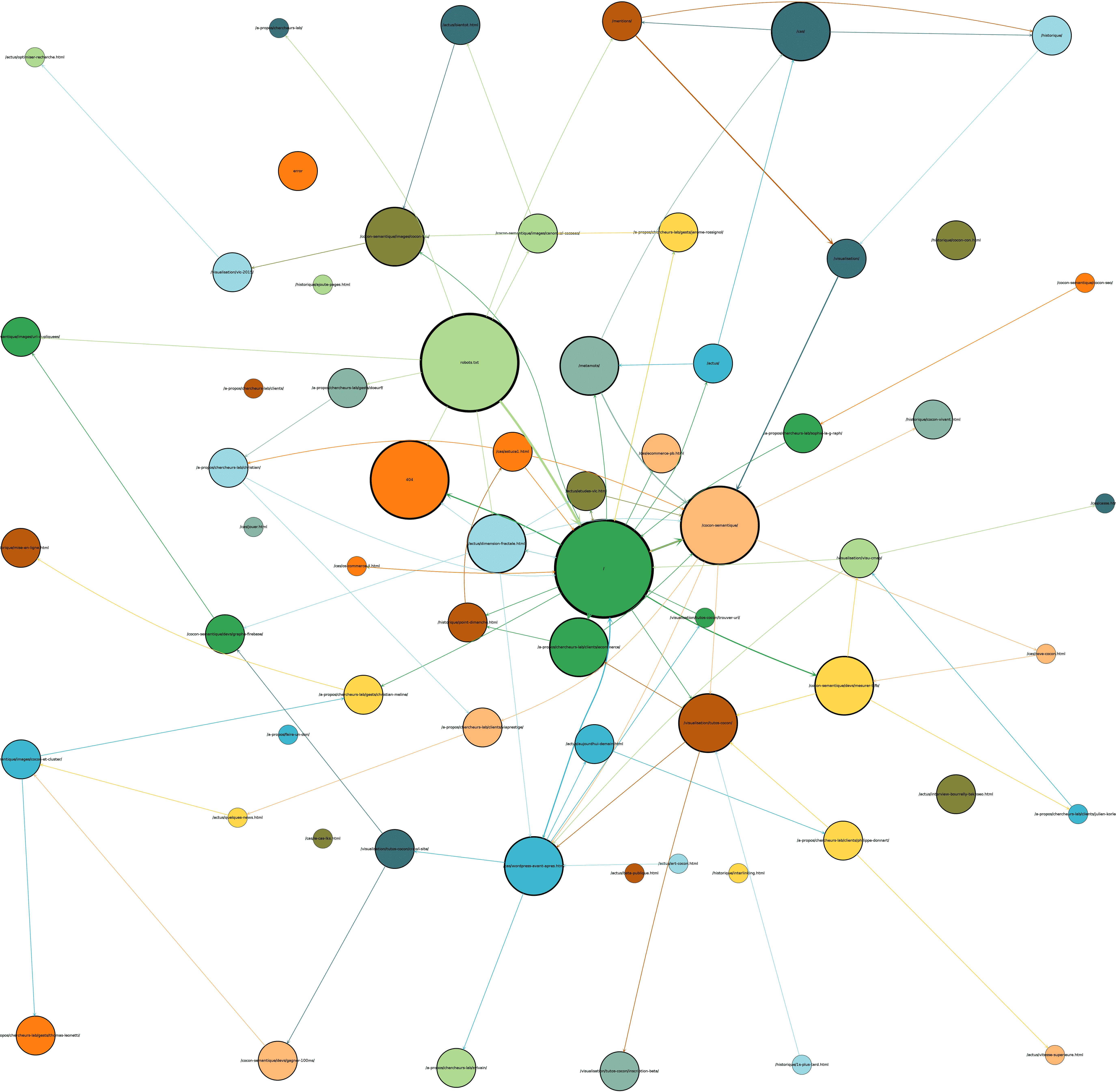
La superposition avec les vues cocon
On peut déjà interpréter plusieurs choses avec ces informations, mais ça reste un peu fouillis : ça manque d’organisation, de stabilité dans les représentations, et on ne voit pas apparaître, par exemple, les pages non crawlées par les bots : elles ne sont pas dans les données !
L’étape suivante était donc de superposer les informations de ces logs aux visualisations cocon.
On peut par exemple surimposer les hits sur les pages (ici sur une semaine):
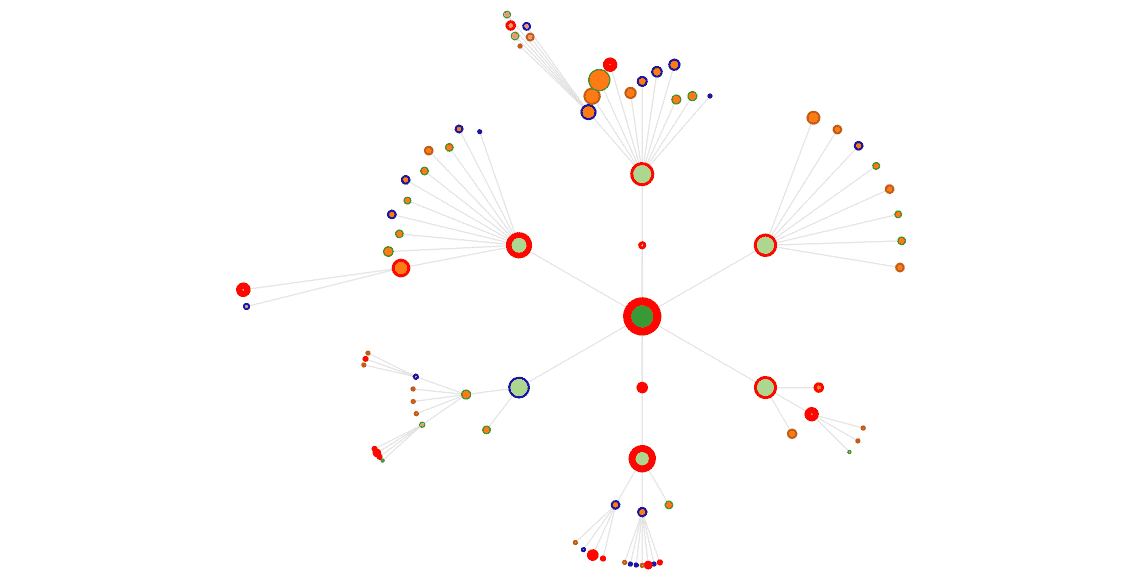
Avec un bord Bleu, les pages qui n’ont pas reçu de hit.
Bord Vert, un seul hit sur la période.
Bord Marron, 2 hits.
Bord Rouge, 3 hits et plus, avec un bord de plus en plus épais avec le nombre de hits.
Ici, on voit nettement quelles pages ont reçu le plus de visites de Google bot, on y reviendra…
On peut également afficher les sessions et les chemins les plus parcourus.
Voici sous forme d’animation ce que ça donne (alternance vue cocon, vue avec hits, puis chemins)
Googlebot, agrégé sur 3 semaines :
Corrélation avec les pages importantes
Une chose importante à remarquer ici, et ça nous a fait drôlement plaisir (notre motto, c’est vous montrer votre site comme le voit Google)
Sur la vue ci-dessus, on voit très bien comment Google bot va voir plus fréquemment certaines pages.
La home, plus que toutes, puis des pages que cocon estime importantes, qu’il affiche plus gros : les catégories par exemple.
Comprendre la logique des bots
Avec ces informations superposées, on voit plein de choses.
Par exemple, que Google va bien crawler les nouvelles pages découvertes (ici par exemple, la page « metamots » qui est récente, a reçu plus de visites que les autres pages de même niveau), et les pages liées; que Googlebot s’agite dès qu’on remanie un peu l’arborescence du site.
Que si, sur un mois complet, il va visiter quasiment toutes les pages du site, pour chaque semaine il n’a visité qu’un petit extrait, mais toujours en respectant grosso modo la priorité du pagerank interne : chaque semaine, il aura visité plusieurs fois la home et les pages « importantes », puis une petite portion du reste.
D’une semaine à l’autre, on ne voit pas trop de différence, mais sur le mois, toutes les pages auront été visitées !
On voit aussi (à confirmer sur d’autres cas) qu’une page comme « à propos », qui est pourtant aussi importante en terme de PR interne que d’autres,
ne reçoit presque pas de visites. Url générique, contenu qui était pauvre : aucune raison d’y passer du temps !
L’analyse comparée de différents bots est elle aussi instructive.
On se rend bien compte, force est de le dire, que Googlebot est très optimisé par rapport à Bing par exemple.
Google économise ses ressources, et les réserves aux pages « importantes ».
Bing lui, se balade plus un peu partout, avec nettement moins de nuances.
Voici par exemple l’animation pour Bing, sur les mêmes 3 semaines :
Beaucoup moins de nuances, un comportement qui est plus chaotique que celui de Googlebot.
ça se voit aussi sur les vues en graphe :
Une semaine pour Bing, à comparer avec une semaine pour Google, première vue graphe de cet article.
Et en animation…
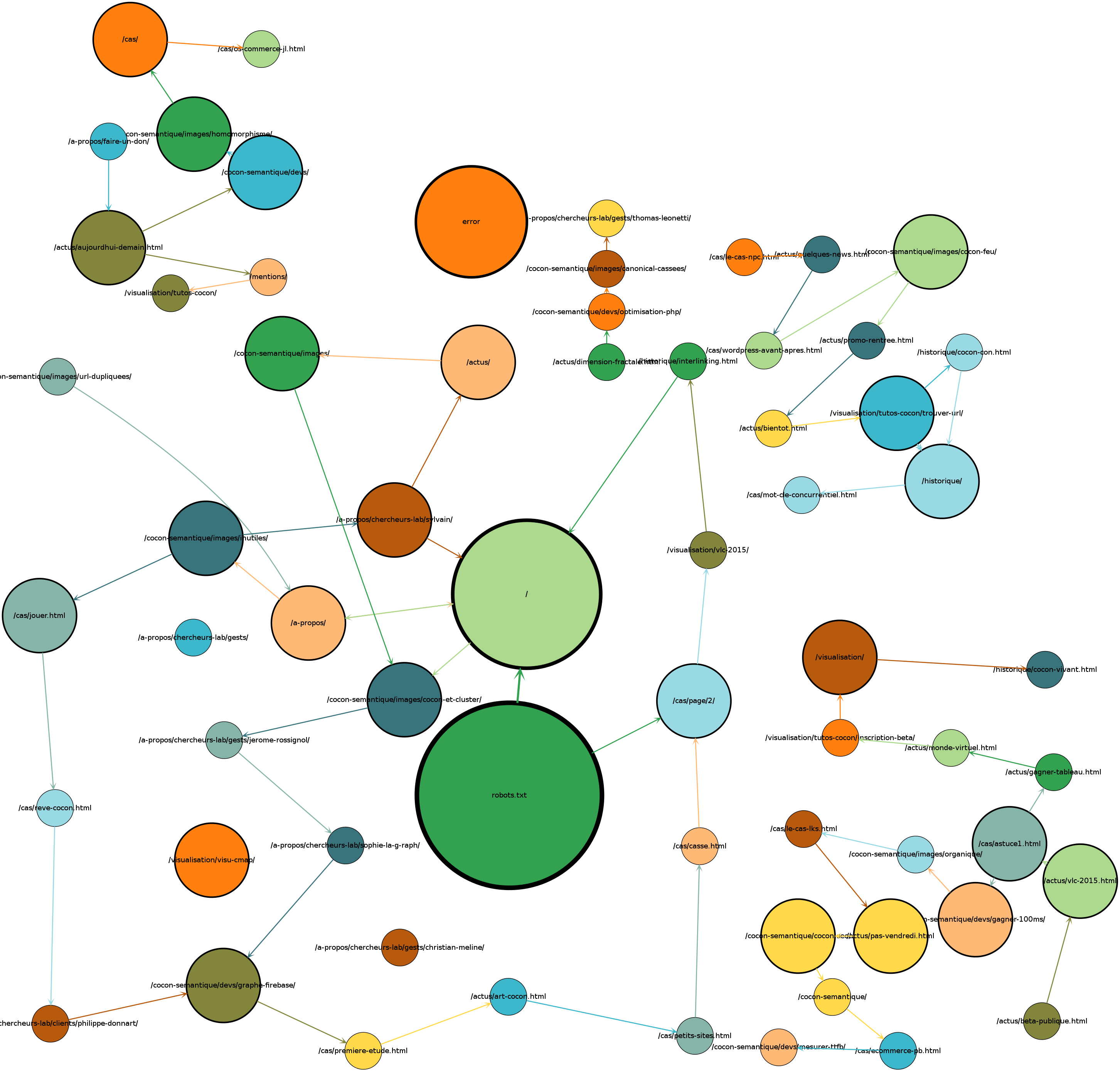
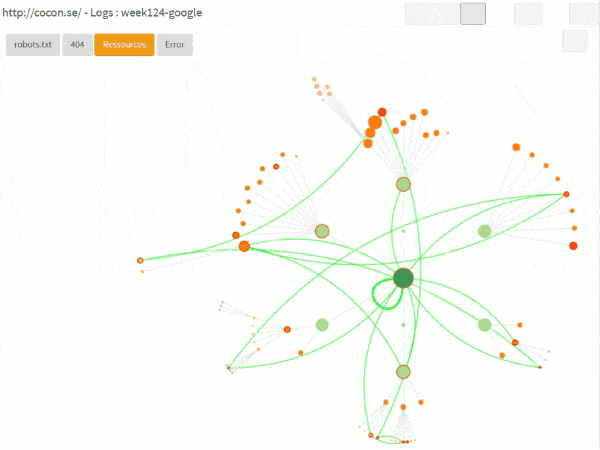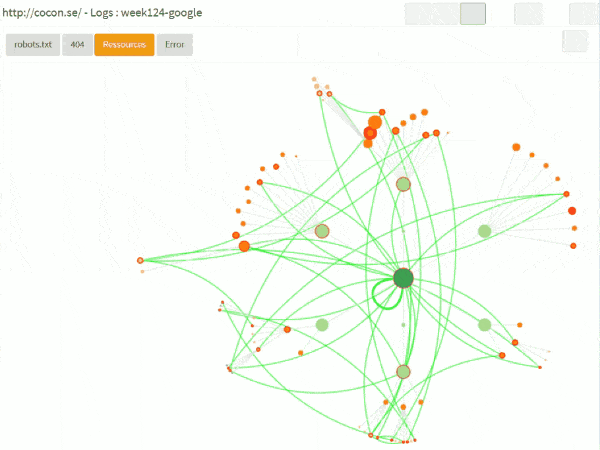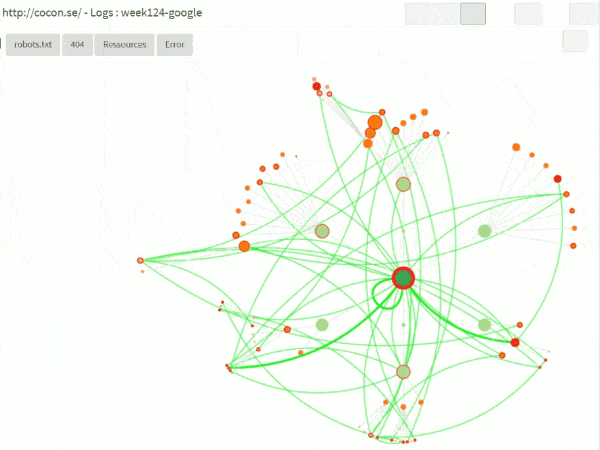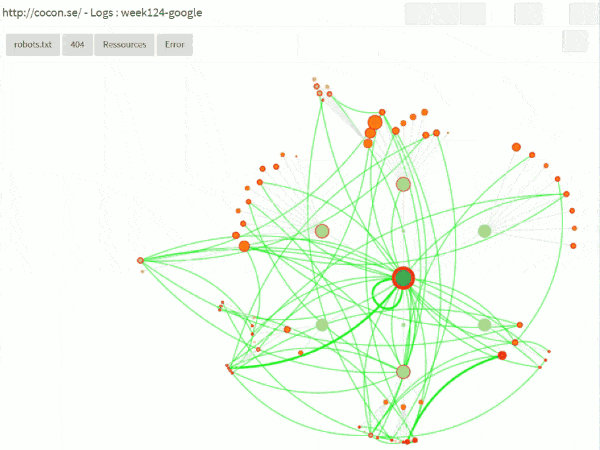
Dans l’interface, on peut également demander de « rejouer » les sessions des bots, en incluant les choses qui ne sont pas forcément sur le graphe cocon, comme
– le robots.txt
– les 404 ou autres erreurs
– les ressources (css, images)
ça donne quelque chose comme ça :
Bots et sessions
Une difficulté quand on analyse le passage des bots, surtout sur des petits sites, c’est comment identifier une session.
Les bots ne donnent pas de referer; ils peuvent attendre longtemps entre une page et la suivante (nettement plus que les 30 minutes qu’on prend comme référence pour les humains).
Si on se base sur l’adresse IP et le timestamp de la requête + une time out, on prend le risque soit de couper une session unique en plusieurs morceaux, soit de cumuler plusieurs sessions. Comme ce comportement du bot varie d’u site à un autre, difficile de tomber juste à tous les coups.
Ce qu’on voit par contre en regardant les sessions de plus près, c’est que Googlebot par exemple, commence toujours une session par un appel au « robots.txt ».
Ensuite seulement, il va traiter ses petites affaires.
J’ai donc choisi d’identifier les sessions en prenant en compte ce paramètre également : Un appel à robots.txt déclenche une nouvelle session, même si l’ip était déjà connue.
Cela permet d’augmenter le timeout de session sans risque pour l’interprétation, et ça passe quel que soit le site.
Utilité pour le SEO
Suivre l’activité des bots sur son site donne évidemment des indications irremplaçables.
En analysant de manière statistique les logs, on peut récupérer des choses simples à analyser :
– pages ignorées
– trop crawlées
– 404, autres erreurs
– pages modifiées mais non visitées
…
Mais en superposant ces informations (et pas juste les stats globales) aux représentations Cocon.Se , on affine encore plus l’interprétation, puisqu’on place les données dans un référentiel connu et stable : l’image de son site, de son arborescence.
Les écarts entre ce que le crawler est censé faire, et ce qu’il fait réellement permet d’éveiller des soupçons sur des erreurs de maillage, des obstacles au crawl d’un bot donné…
Bien entendu, ce qu’on fait ici pour les bots, on peut aussi le faire pour les visiteurs humains… on en fait autre chose, et ça sera l’occasion d’un autre article.
Dans la même série, vous pouvez également consulter :
The English Version of this article : BEA on Sem-Eye.
L’article en Anglais de @VincentTerasi sur le sujet.