
Ca y est, vous êtes inscrit à la béta…
Impatient de prendre votre site en photo ? Peur de faire une erreur ?
Voici un second tuto, tout aussi bref (3min43) : comment lancer son premier crawl, créer différentes visualisations de son site. Les commandes et réglages de base pour commencer.
Voici la vidéo, et en dessous sa transcription.
Note : Depuis la vidéo, il y a eu quelques modifs cosmétiques sur l’interface : les deux colonnes lors de la création du crawl sont inversées, ça semble plus ergonomique ainsi.
Je referais une vidéo quand tout sera stabilisé 😉
Le support
Osez demander !
Le support intégré est le meilleur moyen de nous poser des questions et remonter vos soucis.
Il est disponible ici, depuis votre dashboard, et vous avez dans le bandeau du haut une alerte quand on répond, avec le nombre de messages non lus.
(vous aurez également une notification par email avec le lien direct vers le ticket)
Lancer un crawl
Vos crédits de crawl sont affichés ici. Déroulez pour avoir le détail, ou l’historique complet (crédits cadeau, abonnement mensuel…)
Vous devez avoir du crédit pour lancer un nouveau crawl.
La première étape est ici : « Nouveau crawl ».
Le type de crawl par défaut de votre abonnement est proposé, vous pouvez en changer en changer ici, puis « changer de type » pour valider.
Les limites de crawl sont différentes selon le type choisi.
Le type de crawl défini également quel crédit sera consommé lors du crawl.
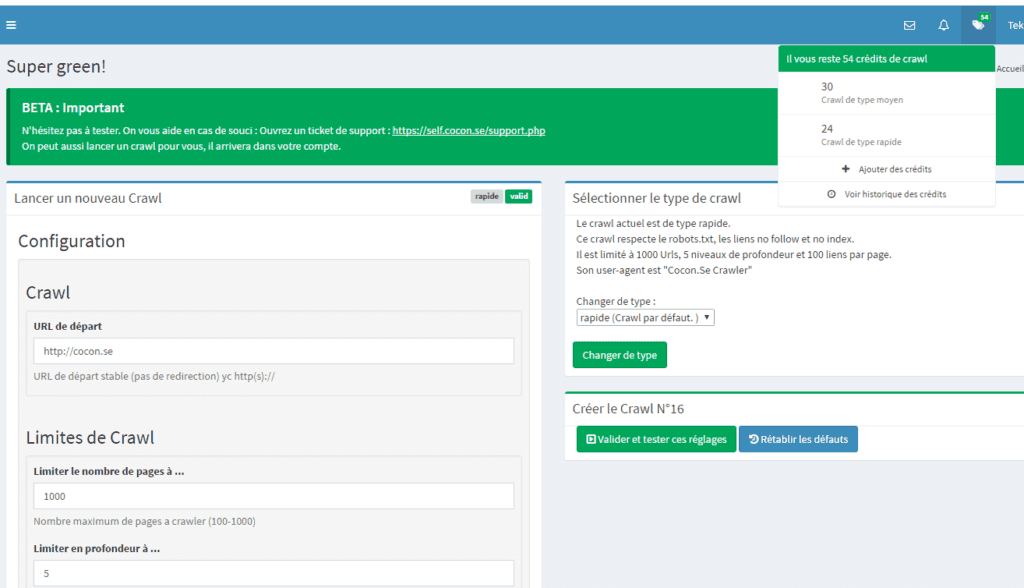
Entrez ensuite votre URL
Il faut une url complète, avec http ou https:// , ainsi que la page précise sur laquelle commencer le crawl.
Précisez les limites de crawl. Vous pouvez monter à 5 taches en parallèle : le crawl sera plus rapide, mais il faut que votre serveur le supporte.
Si vous hésitez, laissez les réglages par défaut.
Le crawl sera limité au host (sous-domaine.domaine.fr) de l’url de départ, mais pas au répertoire de départ.
Si vous voulez limiter à certaines urls (ex: un sous-repertoire) ou exclure des urls, ça se passe dans les règles d’exclusion.
Par défaut, les pages type « plan du site » sont exclues, mais vous pouvez les prendre en compte en supprimant toutes les règles.
Je donnerai dans une autre vidéo des exemples concrets pour l’utilisation de cette fonction.
Vous pouvez laisser le reste par défaut, et tester ce crawl.
Un résumé des réglages est rappelé pour debug. L’aperçu du robots.txt est affiché également,
et vous pouvez confirmer le crawl, ce qui va consommer le crédit.
Vous attendez (ou pas, ça se passe en tache de fond) et quelques minutes plus tard, le crawl est terminé.
Les visualisations
Une première visualisation par défaut, de type « vignette » a été créée, mais vous pouvez en générer d’autres,
soit pour zoomer sur une partie du site, soit pour créer une vue par url, ou treemap.
(vous pouvez lancer plusieurs taches à la suite, on se débrouille pour que ça se passe bien)
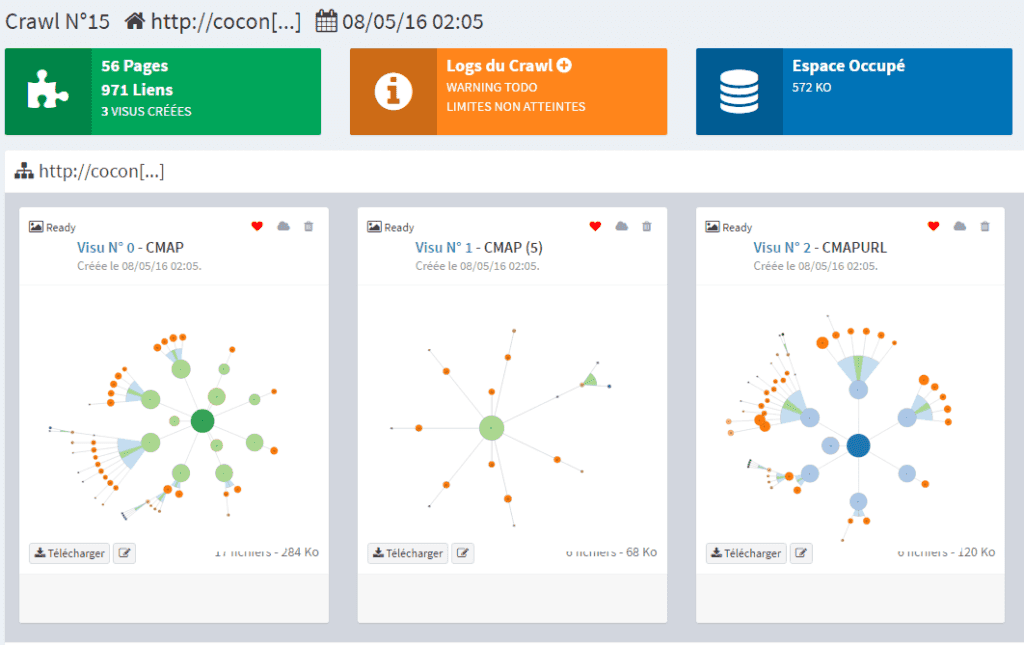
Une autre vidéo donnera des informations plus détaillées sur chaque type de visualisation, et ce qu’on peut y lire.
On a également, en préparation, une méthodologie pas à pas d’analyse. C’est un gros boulot, on est dessus !
Vous voudrez sans doute consulter aussi :